
前回の記事でproc ds2がいらない子扱いしていたところ、一応使っている人もいるらしく一概に役に立たないとはいえないとも意見が来たので、
もう少しds2を触ってみて、なんとか活躍できる場所がないか検討してみました。
せっかく生まれてきたんだもんね・・・ずいぶん大きくなったし・・・活躍・・・したいよね・・・
実際に使ってみる
matrixパッケージを使って重回帰分析を実行する
proc ds2ではmatrixパッケージを使うことで行列を定義できます。これを使うことで行列の転置や逆行列の算出が可能になります。ds2の売りの一つかと思われます。
SAS helpでは重回帰分析を実行する方法が紹介されていたので、それを参考に実施してみました。
データはscikit-learnのbostonデータセットを使用しました。これをSASデータセット化し、重回帰分析を実行します。変数の詳細は以下の通り
| 変数名 | 定義 |
|---|---|
| CRIM | 町別の一人当たり犯罪率 |
| ZN | 25,000平方フィート超に区画された住宅地の割合 |
| INDUS | 町あたりの非小売業(製造業)の面積の割合 |
| CHAS | チャールズ川ダミー変数(地域が川に接している場合は1、そうでない場合は0) |
| NOX | 一酸化窒素濃度(1000万分の1) |
| RM | 一戸当たり平均室数 |
| AGE | 1940年以前に建てられた持ち家の割合 |
| DIS | ボストンの5つの雇用センターまでの加重距離 |
| RAD | 幹線道路へのアクセス性指数 |
| TAX | 10,000ドル当たりの固定資産税率 |
| PTRATIO | 町別の生徒・教師比率 |
| B | 町別の黒人の割合 |
| LSTAT | 人口に占める下層階級の割合 |
| PRICE | 住宅価格 |
住宅価格を目的変数、それ以外の変数を説明変数として回帰係数と切片を推定します。
データの前処理は以下のサイトを参考にしました。

SASで実施するのであればproc regかproc glmを使うことになりますが、今回は回帰係数の推定のみをproc ds2で実施してみます。
重回帰分析の解、すなわち偏回帰係数ベクトルBは以下のように求めることができます
\(行列X^{T}Xが正則のとき、偏回帰係数ベクトルBは\)
\(B = (X^{T}X)^{-1}X^{T}y\)
\(X:説明変数行列\\y:目的変数ベクトル\)
/* 行列宣言のためにレコード数を取得 */
proc sql noprint;
select count(*) into: nobs from boston;
quit;
proc ds2;
data reg(overwrite=yes);
/*説明変数と切片の変数配列*/
vararray double s[14]
intercept
CRIM
ZN
INDUS
CHAS
NOX
RM
AGE
DIS
RAD
TAX
PTRATIO
B
LSTAT;
/*目的変数の配列*/
vararray double m PRICE;
/*行列と使用変数を宣言*/
dcl package matrix x ym y xtx ti xt bm;
dcl double i j;
/*結果格納用配列*/
dcl double result[14];
/*パラメータ名と回帰係数の推定値を格納する変数*/
dcl char(50) parameter;
dcl double estimate;
/*keepステートメントは必ずmethodよりも前に書く*/
keep estimate parameter;
method init();
/*行列のインスタンスを生成*/
x = _new_ matrix(&nobs, 14);
y = _new_ matrix(&nobs, 1);
i=1;
end;
/*runメゾッドでSASデータセットを行列に格納する*/
method run();
set boston;
/*interceptはすべての行で1を格納する*/
intercept=1;
*/x=説明変数、y=目的変数
inメゾッドでSASデータセットから1レコードずつ行列へデータを格納する*/
x.in(s, i);
y.in(m, i);
i + 1;
end;
/*行列計算*/
method term();
xt = x.trans();
xtx = xt.mult(x);
ti = xtx.inverse();
ym = xt.mult(y);
/*回帰係数の推定値のベクトル*/
bm = ti.mult(ym);
/*推定値ベクトルを結果格納用配列に格納する*/
bm.tovararray(s);
/*変数名と推定値を出力*/
do j=1 to 14;
parameter=vname(s[j]);
estimate=s[j];
output;
end;
end;
enddata;
run;
quit;
PRICE;
/*行列と使用変数を宣言*/
dcl package matrix x ym y xtx ti xt bm;
dcl double i j;
/*結果格納用配列*/
dcl double result[14];
/*パラメータ名と回帰係数の推定値を格納する変数*/
dcl char(50) parameter;
dcl double estimate;
/*keepステートメントは必ずmethodよりも前に書く*/
keep estimate parameter;
method init();
/*行列のインスタンスを生成*/
x = _new_ matrix(&nobs, 14);
y = _new_ matrix(&nobs, 1);
i=1;
end;
/*runメゾッドでSASデータセットを行列に格納する*/
method run();
set boston;
/*interceptはすべての行で1を格納する*/
intercept=1;
*/x=説明変数、y=目的変数
inメゾッドでSASデータセットから1レコードずつ行列へデータを格納する*/
x.in(s, i);
y.in(m, i);
i + 1;
end;
/*行列計算*/
method term();
xt = x.trans();
xtx = xt.mult(x);
ti = xtx.inverse();
ym = xt.mult(y);
/*回帰係数の推定値のベクトル*/
bm = ti.mult(ym);
/*推定値ベクトルを結果格納用配列に格納する*/
bm.tovararray(s);
/*変数名と推定値を出力*/
do j=1 to 14;
parameter=vname(s[j]);
estimate=s[j];
output;
end;
end;
enddata;
run;
quit;上記のプログラムを実行するとデータセットregが作成され、パラメータの推定値が格納されます。proc ds2でデータセットを作成するとsas studioで出力データセットのタブが表示されないんですよね・・・いちいちライブラリから参照しないといけないのがめんどくさい。なんで対応してないんだろう。

同様の解析をproc regでも実施してみます。
proc reg data=boston;
model price=CRIM
ZN
INDUS
CHAS
NOX
RM
AGE
DIS
RAD
TAX
PTRATIO
B
LSTAT;
run;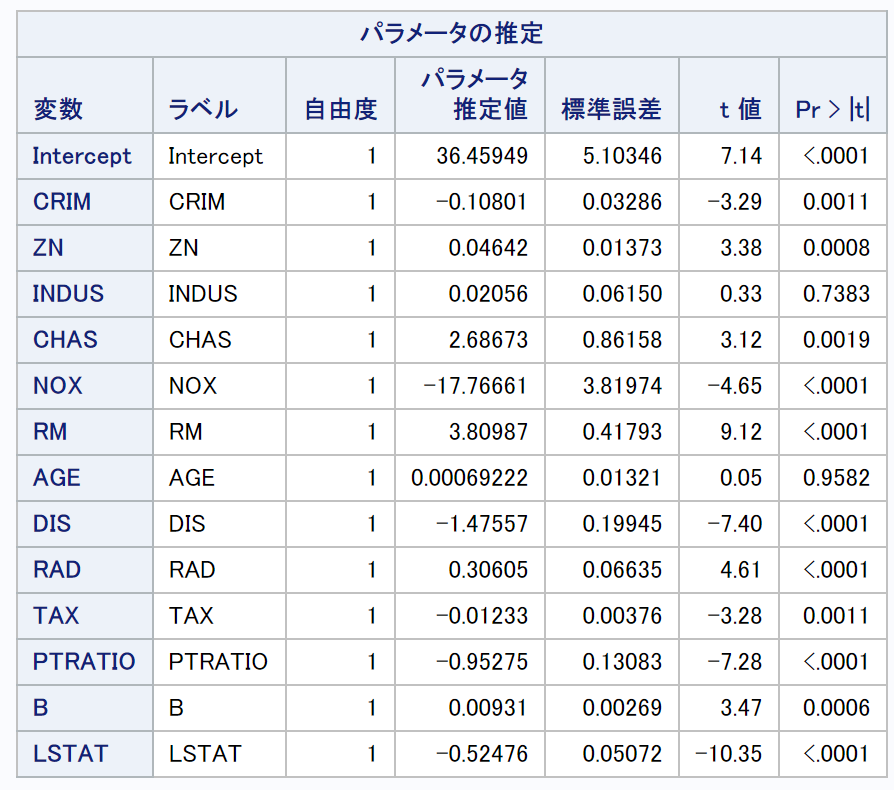
推定値は一致しているようです。やったね!
データセットの変数を加工する
既存のデータステップっぽいことをproc ds2でも実装してみます。今回は東京都の新型コロナウィルス感染者のcsvデータをあらかじめ取り込んだデータセットを加工し、
フォーマットや変数属性を設定してみました。

まずは通常のデータステップでやってみます。csvファイルはproc importで取り込みました(かってに変数型が決まるので面倒ですが・・・)
/*CSVファイル読み込み*/
PROC IMPORT DATAFILE=REFFILE replace DBMS=CSV OUT=WORK.IMPORT;
GETNAMES=No; datarow=2; guessingrows=max;
RUN;
proc format;
/* 年齢区分 */
value agec 1="10歳未満"
2="10代"
3="20代"
4="30代"
5="40代"
6="50代"
7="60代"
8="70代"
9="80代"
10="90代"
11="100歳以上"
99="不明" ;
run;
data cases;
attrib
caseid length=8 label="No"
prefid length=8 label="全国地方公共団体コード"
pref length=$50 label="都道府県"
city length=$50 label="市町村"
publish length=8 label="公表日" format=yymmdds10.
publish_y length=8 label="公表年"
publish_m length=8 label="公表月"
onset length=8 label="発症日" format=yymmdds10.
confirm length=8 label="確定日" format=yymmdds10.
address length=$50 label="居住地"
agegrp length=8 label="年代" format=agec.
gender length=$1 label="性別"
work length=$50 label="職業"
status length=$200 label="状態"
symptom length=$200 label="症状"
travel length=$1 label="渡航歴の有無"
contact length=$1 label="接触歴の有無"
comment length=$500 label="備考"
discharge length=$1 label="退院の有無" ;
set import;
caseid=var1;
prefid=var2;
pref=var3;
city=var4;
publish=var5;
publish_y=year(var5);
publish_m=month(var5);
onset=var6;
confirm=var7;
address=var8;
select (var9);
when("10歳未満") agegrp=1;
when("10代") agegrp=2;
when("20代") agegrp=3;
when("30代") agegrp=4;
when("40代") agegrp=5;
when("50代") agegrp=6;
when("60代") agegrp=7;
when("70代") agegrp=8;
when("80代") agegrp=9;
when("90代") agegrp=10;
when("100歳以上") agegrp=11;
otherwise agegrp=99;
end;
select (var10);
when("男性") gender="M";
when("女性") gender="F";
otherwise gender="U";
end;
work=var11;
status=var12;
symptom=var13;
if var14="1" then travel="Y";
if var15=1 then contact="Y";
comment=var16;
if var17=1 then discharge="Y";
drop var:;
run;これをds2に置き換えると以下のようになります。新しい変数型であるdate, integerを使うようにしました。
proc ds2;
data case2(overwrite=yes);
/*attribステートメントの代わりにdclステートメントを使う*/
dcl integer caseid having label 'No';
dcl integer prefid having label '全国地方公共団体コード';
dcl char(50) pref having label '都道府県';
dcl char(50) city having label '市町村';
dcl date publish having label '公表日' ;
dcl integer publish_y having label '公表年';
dcl integer publish_m having label '公表月';
dcl date onset having label '発症日';
dcl date confirm having label '確定日' ;
dcl char(50) address having label '居住地';
dcl integer agegrp having label '年代' format agec.;
dcl char(1) gender having label '性別';
dcl char(50) work having label '職業';
dcl char(200) status having label '状態';
dcl char(200) symptom having label '症状';
dcl char(1) travel having label '渡航歴の有無';
dcl char(1) contact having label '接触歴の有無';
dcl char(500) comment having label '備考';
dcl char(1) discharge having label '退院の有無';
/*dropは必ずメゾッドの前に指定する*/
drop var:;
method run();
set ex.case_tokyo;
caseid=var1;
prefid=var2; pref=var3; city=var4;
/*日付値の型変換関数はdouble型しか引数として取れないため、to_doubleで一度double型に変換する*/
publish=to_date(to_double(var5));
publish_y=year(to_double(var5));
publish_m=month(to_double(var5));
onset=var6;
confirm=var7;
address=var8;
select (var9);
when('10歳未満') agegrp=1;
when('10代') agegrp=2;
when('20代') agegrp=3;
when('30代') agegrp=4;
when('40代') agegrp=5;
when('50代') agegrp=6;
when('60代') agegrp=7;
when('70代') agegrp=8;
when('80代') agegrp=9;
when('90代') agegrp=10;
when('100歳以上') agegrp=11;
otherwise agegrp=99;
end;
select (var10);
when('男性') gender='M';
when('女性') gender='F';
otherwise gender='U';
end;
work=var11;
status=var12;
symptom=var13;
if var14='1' then travel='Y';
if var15=1 then contact='Y';
comment=var16;
if var17=1 then discharge='Y';
end;
run;
quit;attribステートメントは以下のように書き換える必要があるみたいですね。あとラベル文字列はシングルクォーテーションで囲む必要があります。ダブルクォーテーションはNGです。
dcl 変数型 <変数名> having format フォーマット名 informat インフォーマット名 label 'ラベル名';所感
matrixパッケージはごみ
初めてproc ds2で行列計算を実施してみた感想は、、、、すげーめんどくさいです。
まずSASデータセットと行列を相互変換するメゾッドが用意されていないのが致命的すぎます。runメゾッドで行単位で一つずつデータを行列へ格納する命令を書かないといけないため、明らかに他言語よりもコードが長くなります。また結果をデータセットに格納するにも 行列→変数配列→SASデータセットの順で変換しなくてはならないのはあまりスマートとは呼べないと思います。
ユーザーがパッケージを自作すればもう少し簡単になりそうですが・・・それつくる人いるの?
また用意されている行列演算は転置と逆行列、四則演算くらいしかないため、ds2で複雑な行列演算を行うのは厳しいと言わざるを得ません。単位行列の生成や特異値分解など線形代数関連で実施する操作はメゾッドとして提供されておらず、自力でパッケージを作るしかありません。
予想なんですけど、SAS社としてはパッケージを自作できるようになっているんだからユーザーが自発的にパッケージの開発と公開をしてくれるんじゃないかと思ってたんじゃないの?甘いよ。
IMLの代わりにはならないでしょうね。複雑な行列計算をproc ds2で実装するメリットを全く感じませんでした。
活用事例がすくなすぎる
検索してもパッケージを活用した効率的な開発の実例とか、実際にデータステップのコードをds2に置き換えて実行してみたとか、そういう活用事例がまー全然なくて・・・
記事を書くのが正直苦痛でした。なんでエラーになるのか原因を探るのがほんとに時間かかるし、結局既存のデータステップでいいじゃんってなる可能性が非常に高いですね。
stackoverflowでも議論されているのか見ましたが、”proc ds2″で17件しかなかったし、前回の記事で述べた通りgoogle検索でも大してヒットしなかったので、海外で議論されているとは言えない気がします。日本の文献も文法を紹介しているブログがあるくらいで、これじゃ開発するのは難易度高いと言わざるを得ません。

型変換(キャスト)には注意
変数型が増えた関係で型変換のときにトラブルが続出しそうです。SAS base環境で開発する場合は特にそう。
SAS baseでは、ds2でdate型とかinteger型のような新しい型を指定したとしても強制的にChar型かdouble型に変換されるようです。Baseでは新しい型には対応していないようですね。
かといって最初からdclステートメントでcharとdoubleのみを指定すると、今度はrunメゾッドで型変換して新規変数を作成するときにエラーが発生するので、はやりSAS base環境であっても適切な変数型に指定するのは必須のようです。
ds2内で使用できる関数はdouble型などds2固有の変数型しか引数として利用できないものもあるようなので、通常のSASデータセット由来の変数を加工する場合は型変換しないとエラーになります。
例えばデータステップの「publish_y=year(publish)」は日付値から年を取り出していますが、これをそのままds2で実行するとエラーになり、「日付または時間の型の変換は無効です。」と表示されます。
to_double関数で一度変数をdouble型に変換すれば、正常に年を取り出せます。
SQLクエリが使えるのはGood
set ステートメントにSQLクエリが使えるのはいいかなと思いました。 実際使っている人もいるらしいです。
データの抽出はSQL、データの加工はSASいったかんじで各言語を適材適所に使用できるのは良いと思いました。
これはds2の一番のメリットではないでしょうか?SQLの活用を事実上強制するので、mergeステートメントのクソ仕様に振り回される心配はなくなります。
結論
有用な点もないわけではありませんが、現時点ではやはりds2に乗り換える必要性は薄い気がします。もっと活用事例が出てきて利用できそうだったら検討すれば良いのですが、今後もそのような取り組みが継続するとは思えません。私の場合は検索してもなかなか情報がでてこないし、行列パッケージがあまりにもうんこすぎてちょっと使う気が失せましたね。
proc ds2は従来のSASデータセットが基盤になっているため、現状は行列の取り扱いがしやすいとはとても呼べないと思います。結局Rかpandasを使うことになるでしょう。
変数型が豊富なのでSAS base以外の製品と併用する場合、特にSAS viyaライセンスを保有しているかつCAS(Cloud analytic service)を利用する一部の人だったら活用できるかもしれませんが、SAS baseで完結してしまう業務であればメリットは皆無なので今後も普及しないと思います。じゃSAS viyaとかCASのユーザー数が増えればワンチャンあるかといえばそうでもないでしょう。SAS viyaが必要になるようなビックデータ関連業務に従事する人は大抵別言語も習得しているでしょうから、わざわざds2を習得する理由が思いつかないです。
ds2のセールスポイントであるパッケージも実用例がいまいち見つからなくて何とも言えません。これもfcmpやマクロでも代用できるといわれればそれまででしょうし・・・
結局のところオブジェクト指向の概念をSAS環境に導入することに何のメリットがあるのかがわかりませんでした。
定型処理をクラス化するのはいいのですが、SASの歴史が長い分今のデータステップで効率よく開発する工夫を各社考えてきたわけで、、、長年の努力の結晶である既存のコードを書き換える手間をかけて得られるメリットを提示していただかないと誰も使いません。




