<2023/7/9>
記事を修正しました。
SASのデータステップは行指向の処理を実施するのは簡単ですが、複数の行からデータを取得するのは苦手です。
retainステートメントを使用すれば処理しているレコードよりも前のレコードの値を取得することはできますが、後のレコードの値を取得することは
かなり難しいと思います。
一方SQLはSASのデータステップよりも多くの結合方法をサポートしており、複数行のデータを参照して集計することが簡単にできます。特に大きな違いとなるのが非等価結合(non-equi-join)です。
複数行のデータを参照したい場合は非等価結合を用いると簡単に記述できます。SASだけでもできなくはないのですが、処理が煩雑になりがちなので
SQLを用いることを推奨します。覚えておけばRやpython環境でも作業できるはずです。
非等価結合とは
非等価結合(non-equi-join)は等価演算子を用いない結合条件を含むテーブルの結合を指します。逆に等価演算子のみを用いる結合条件で結合する場合は等価結合と呼びます。
等価演算子はいわゆるイコール(=)のことです。
SASのマージステートメントやハッシュを使った結合は等価結合です。つまりマージキーとして指定された変数の値が一致したレコードが結合対象となります。
それに対し非等価結合は不等号やbetweenなどのイコール以外の演算子を結合条件に利用します。これはSASのマージステートメントではサポートされていません。
select * from dat1 inner join dat2 on <イコール以外の演算子を含む結合条件>; select * from dat3 cross join dat4 where <イコール以外の演算子を含む結合条件>;
一般的に非等価結合は等価結合よりもパフォーマンスが悪いとされています。また意図した結合結果になっているかはよく確認したほうが良いでしょう。
臨床統計の場合ですと、結合条件に日付の範囲指定を加えるときにこの結合を使うことが多い印象です。あと自己結合(self join, 同じデータセット同士の結合)と併用するケースも多いかな。
なお非等価結合は結合条件の話なので結合モード(left join, right join, inner join, cross join)の指定はありません。
本ブログでは非等価結合はcross joinで記述していますが、innner joinで置き換えても動作すると思います。個人的には非等価結合を実施するときはcross joinを使うというルールにしておけばテキスト検索でどこで非等価結合を実行しているか後でわかるのでこのような形で書いています。
実用例
累積投与量を算出する
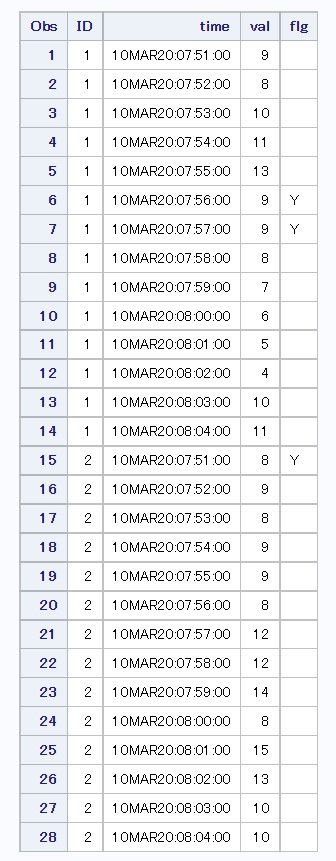
以下のようなデータセットがあります。
| 変数 | 定義 |
|---|---|
| USUBJID | 患者ID |
| EXSEQ | 投与連番 |
| EXSTDTM | 投与開始日時 |
| EXDOSE | 投与量 |
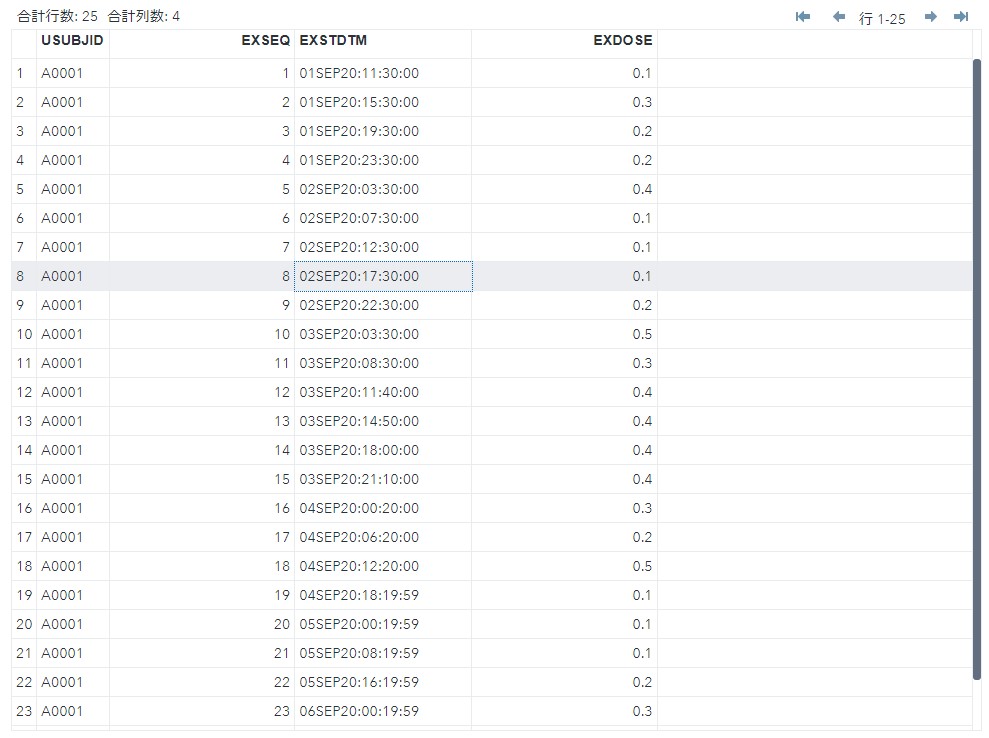
このデータから過去24時間以内の累積投与量を算出してみましょう。
例えばEXSEQ=8の投与日時は2020/09/02 17:30に投与したので、EXSEQ=8における過去24時間の累積投与量とは 2020/09/01 17:30から2020/09/02 17:30の期間に投与した薬物量の合計となります。
EXSEQ=3から8までの投与量の合計なので、累積投与量は1.1となります。
この計算をデータステップだけで実施は多分無理じゃないかな。症例ごとの累積投与量なら可能ですが。
プロシジャを使うのであればproc expandで行けそうかと思いましたが、これはあらかじめ設定した time window内のレコードの値を合計することはできますけど、time windowは日付に依らず固定なので今回の目的では不可です。例えば基準のレコードから5レコード前までのデータを合計するとかならproc expandでもできますが、今回のように等間隔で投与していない場合はtime windowがレコードによって変わるので使えません。もちろんproc transposeで無理やり変数を横方向に並べるのはなしですよ?
かなり難しいようにみえますが、SQLなら簡単です。
まず同一テーブル同士をcross joinして合計対象となるレコードを結合します。自己結合(self join)というやつですね。
asキーワードでデータセットに別名を与えることで、データセットをaとbとして区別できるようにします。
whereステートメントでデータセットaの投与日時から過去24時間(日時値なので24 * 60 * 60 秒差し引くことで24時間前の日時値を算出しています)のデータセットbのレコードのみを結合します。
必要はありませんが今回は処理の中身を理解するためにデータセットbのEXSEQとEXSTDTMも保持しています。
Copyproc sql noprint; create table tmp as select a.USUBJID, a.EXSEQ, a.EXSTDTM, b.EXSEQ as EXSEQ_B, b.EXSTDTM as time, b.EXDOSE from EX as a cross join EX as b where a.USUBJID = b.USUBJID and b.EXSTDTM between a.EXSTDTM -24*60*60 and a.EXSTDTM order by a.USUBJID, a.EXSEQ, b.EXSEQ; quit;
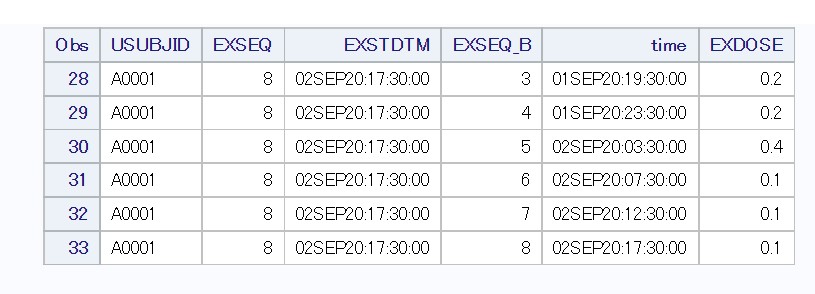
このデータセットのEXSEQ=8のレコードを確認してみましょう。EXSEQ_Bを確認するとEXSEQ3~8のレコードが結合されているのがわかります。
後はUSUBJID, EXSEQ, EXSTDTM毎に投与量を合計します。proc sqlはwindow関数が使用できないのでこの方法が最適解かと思います。
Copyproc sql noprint; create table cum as select USUBJID, EXSEQ, EXSTDTM, sum(EXDOSE) as cumdose from tmp group by USUBJID, EXSEQ, EXSTDTM; quit;
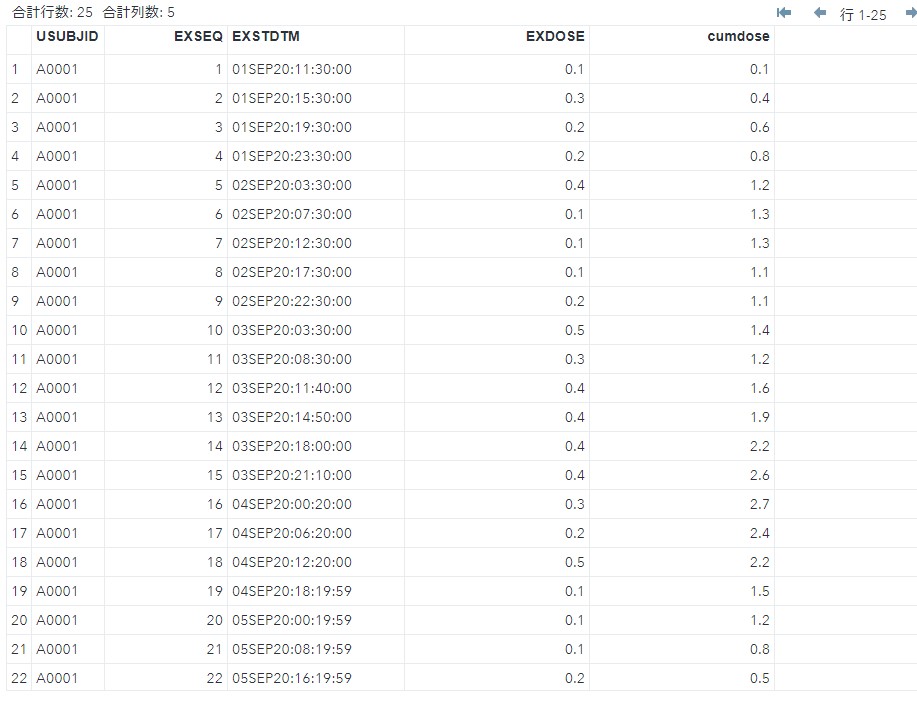
サブクエリを活用し、保持する変数を見直すと以下のようになります。これで完成です。
Copyproc sql noprint; create table cumdose as select USUBJID, EXSEQ, EXSTDTM, EXDOSE, sum(dose) as cumdose from (select a.USUBJID, a.EXSEQ, a.EXSTDTM, a.EXDOSE , b.EXDOSE as dose from EX as a cross join EX as b where a.USUBJID = b.USUBJID and b.EXSTDTM between a.EXSTDTM -24*60*60 and a.EXSTDTM) group by USUBJID, EXSEQ, EXSTDTM, EXDOSE; quit;
データセットの自己結合を活用することで今回のような累積値だけでなく移動平均なども算出することができます。
whereステートメントの条件次第で様々な計算に活用できるでしょう。
とりあえず複数レコードを利用する計算はproc SQLの利用を考えると覚えておけば良いと思います。
類題(2022/03/19追記)
似たような処理を他の方も実施していました。引用元のブログではハッシュオブジェクトを利用していましたので、
私はSQLで書いてみます。
詳細は以下の記事をご確認ください。
対象レコードのvalが10未満であり、対象レコードから5分先までのレコードにvalが10以上のレコードが存在しないとき、フラグを立てます。
SQLで同様の処理を実施するには累積投与量の算出と同様にself joinを活用すれば実現できますが、フラグを立てる必要があるのでcase式も使う必要があります。
まずデータセット(別名a)と同じデータセット(別名b)を結合します。この時結合条件としてaの時間から5分先のレコードを指定します。
timeは日時値なので秒で指定しています。
Copyproc sql noprint; create table _wk1_sql as select a.*, b.time as b_time, b.val as b_val, case when a.val < 10 and b.val <10 then 1 else 0 end as _flg from temp as a cross join temp as b where a.ID = b.ID and b.time between a.time and a.time + 60*5 ; quit;
実行結果の一部を見てみましょう。
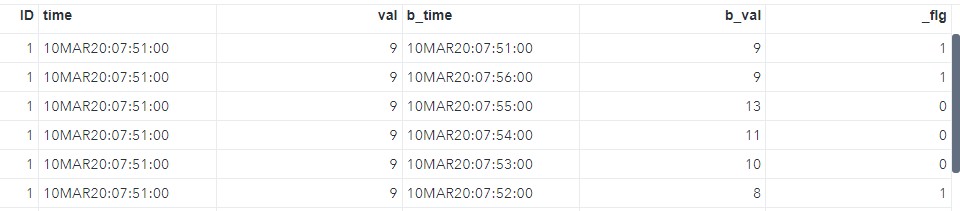
timeが7:51なので、7:51~7:56までのレコードが対象となります。b_timeを見ると確かに対象レコードが結合されていますね。
カラム_flgには、case式を利用して別名aのvalが10未満かつ別名bのvalが10未満の場合は1、そうでない場合は0を格納します。
対象レコードのvalが10未満であり、5分先までのデータに10以上valが存在しないというのは、_flg=0のデータが存在しないと言い換えることができます。
flg=0が存在するかどうかはtime毎のflgの最小値を見れば判定できます。flgの最小値が1の場合は、_flg=0のレコードが存在しないということですので、group byでグループ化して最小値を求めた後、case式を使ってフラグ変数flgに"Y"を格納します。
以上を踏まえると最終的なクエリはこのようになりました。
Copyproc sql noprint; create table wk1_sql as select a.*, case when min(_flg)=1 then "Y" else "" end as flg from ( select a.*, case when a.val < 10 and b.val <10 then 1 else 0 end as _flg from temp as a cross join temp as b where a.ID = b.ID and b.time between a.time and a.time + 60*5) group by a.ID, a.time, a.val; quit;
クエリ結果は以下の通りです。引用元のブログの結果と一致しました。