
CASE式を使うことでこれまでproc transposeで実施していた集計結果の転置をSQLでも実施することができます。
この処理自体はSASだけで実現できるためSAS環境であればこの方法である必要はないですが、SAS以外の環境で解析を実施する可能性
がある人は本方法のロジックは知っておいた方が良いでしょう。
proc trasposeを使う場合
今回はテストデータcarsを使って、車種と製造地域ごとに製品数と燃費(MPG_city)の平均値を算出します。変数Asia, Europe, USAに結果を格納し、変数Typeには車種を格納します。
Copyproc freq data=sashelp.cars; tables type*origin / out=out1; run; proc transpose data=out1 out=out2; var count; id origin; by type; run; *欠損をゼロに置換する; data freq_sas; set out2; if Asia=. then Asia=0; if Europe=. then Europe=0; if USA=. then USA=0; keep type Asia Europe USA; run; title '製造地域別および車種別の製品数'; proc print data=freq_sas;run;
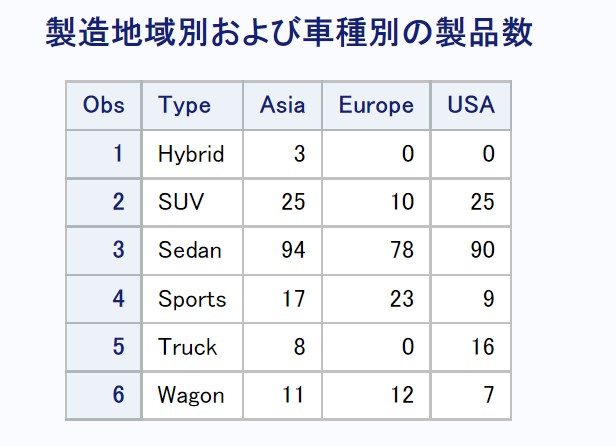
proc freqからのproc transposeをつかう最も一般的な方法です。proc transposeは混乱する人がいるので、byは行を定義する変数を、idは列名を定義する変数を指定すると教えてます。
わかりやすいのかどうかは自信ないけど
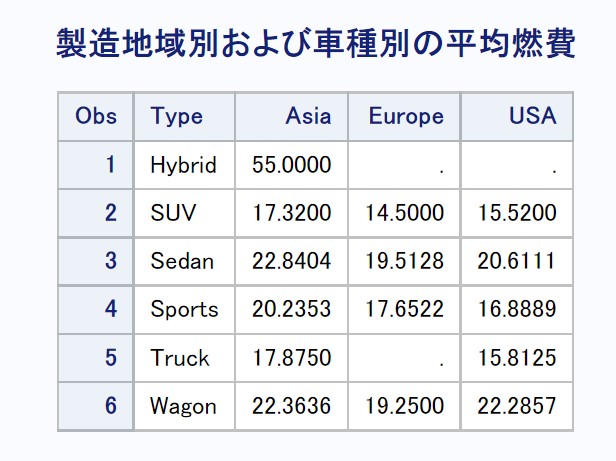
燃費の集計もproc meansを使う以外は流れは同じです。
Copyproc means data=sashelp.cars nway; var MPG_city; class origin type; output out=stat1 mean=mean; run; proc sort data=stat1 ; by type origin; run; proc transpose data=stat1 out=mean_sas(keep=type Asia Europe USA); var mean; id origin; by type; run; title '製造地域別および車種別の平均燃費'; proc print data=mean_sas;run;
proc sqlを使う場合
proc sqlを使う場合は集計と結果の転置を両方とも実行できます。
転置はcase文を使って集計対象かどうかを判定して値を読み替えた後グループごとに要約することで実現できます。
前回記事で紹介した方法そのままですが、これを活用するだけでproc transposeと同等の操作を実現できます。
CASE式は要約統計量関数の引数として指定することができます。これがCASE式の汎用性を爆上げします。
例えばAsiaの製品数を算出したい場合は case式でOrigin=Asiaの場合は1、そうでない場合は0に読み替えます。
これをsum関数を使ってtype毎に合計することでOrigin=Asiaの製品数のみを指定したカラムに格納することができます。
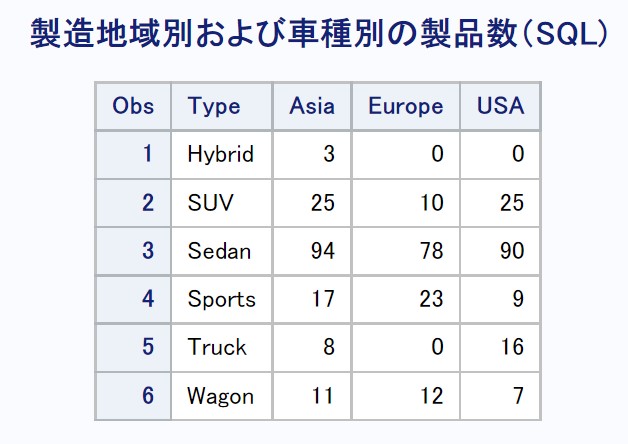
Copyproc sql noprint; create table freq_sql as select type, sum(case when origin='Asia' then 1 else 0 end) as Asia, sum(case when origin='Europe' then 1 else 0 end) as Europe, sum(case when origin='USA' then 1 else 0 end ) as USA from sashelp.cars group by type; quit; title '製造地域別および車種別の製品数(SQL)'; proc print data=freq_sql;run;
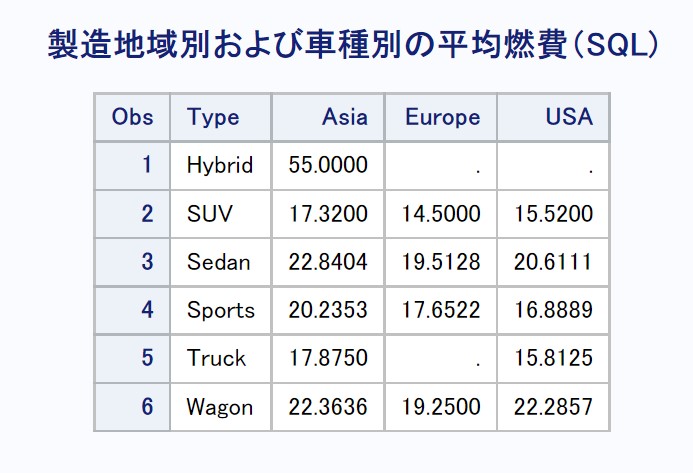
平均値を算出する場合はcase式で条件に合致する場合は燃費、合致しない場合は欠損に読み替えてから平均値を算出します。
欠損は平均の算出からは除外されますので、結果的に特定の条件(今回の場合は指定した製造地域)に合致した燃費のみが計算対象となります。
Copyproc sql noprint; create table mean_sql as select type, mean(case when origin='Asia' then MPG_city else . end) as Asia, mean(case when origin='Europe' then MPG_city else . end) as Europe, mean(case when origin='USA' then MPG_city else . end ) as USA from sashelp.cars group by type; quit; title '製造地域別および車種別の平均燃費(SQL)'; proc print data=mean_sql;run;
proc transposeで全然OK
コードを見る限りだとSQLのほうがコード量が少なく1回のクエリですべて実現できているので、SQLに置き換えたほうが良さそうですが、私は別にproc transposeでもいいんじゃないかなとは思います。
どっち使っても結果は変わりませんし、大幅にパフォーマンスが向上するというケースもまれだと思います。proc transposeはprefixオプションで指定した文字列に連番を付与したものを転置後の文字列として設定できますし、そもそも転置後にさらに加工するケースも多いのでコードがシンプルになるくらいのメリットしかないかなという印象です。
あとSQLのほうがデバックがしずらいのでCASE式があまりにも複雑になるようならデータステップで実施したほうが良いと思います。構造を変えるだけの操作はSQLの本来想定された使い方じゃないと思います。
ただしcase式を使って読み替えた後要約するというテクニックは非常に有用で、SQLだけでなくRやpythonでも通用するので知ってて損はないと思います。というか知ってたほうが良いです。
Rだとdplyr, pythonだとpandasを使用すればSQLのgroup by句と同じものが使えるので、環境が変わっても同じように解析できるはずです。


